The Craft of AI
The Return of the Eval
If you wrote off AI evals, think again.
By Luke Lin · · 6 min read
Last week I stood in a packed room at Shack15 in San Francisco for Arize:Observe. 700+ builders, and the whole center of gravity was one thing: evaluating and monitoring AI agents.
A year ago, the loudest voices in my feed were calling evals dead. Standing in that room, it was obvious they’d come back. AI teams had ridden the hype and the disillusionment, and now they’re seeing the mechanism for what it is.
Evals are your ML performance metrics for agents, the precision and recall and F1 of the thing. They don’t make your product succeed; you still have to do that. But you can’t run a performant agent without them.
The evals saga
Here’s how we got here.

Episode IV: A New Eval
Evals are everything.
In 2024, the consensus was loud. Hamel Husain wrote that your AI product needs evals, full stop. Evals were “the new unit test.” Greg Brockman said they’re “surprisingly often all you need.” Garry Tan called them “emerging as the real moat for AI startups.” If you were building, you were told you had to have them.
In the GPT-4 era, when reasoning was still shaky, teams doubled down. Evals were going to be the thing that differentiated agent performance, and we all believed it.
Episode V: The Models Strike Back
Evals are dead.
Then came the backlash. Teams burned weeks hand-labeling golden datasets, and a single reasoning jump made failure modes vanish overnight. Why maintain a test suite against a target that keeps moving? Alex Reibman caught the mood in a post titled “Evals are a scam.” The frustration was real, and it was earned.
The logic was simple. Reasoning jumps from the foundation models would erase any moat you’d built with detailed evals, and take your tuning time and money with them.
Episode VI: Return of the Eval
Okay, evals are useful.
The position that settled was quieter and more nuanced. You don’t need thousands of labeled golden points. The Pragmatic Engineer’s guide to evals, built on Hamel’s work across 40-plus companies, starts with error analysis: spend thirty minutes reading 20 to 50 real outputs, name the handful of ways your system actually breaks, and write a check for each.
Yes, we need evals. No, we don’t need over-built golden datasets. A few good data points give enough signal to tell you how well the agent is performing.
The belief changed underneath the practice. Teams used to invest in evals for a fine-tuning moat. Reasoning jumps killed that story. What’s left is more durable: evals are the telemetry you measure to know how your agent is doing.
Which brings us back to that room at Observe 2026.
The eval is back, bigger than before, and the labs are leading it. Anthropic now ships an engineering guide to evals for agents that makes the plain case: “Without evals, it’s easy to get stuck in reactive loops, catching issues only in production, where fixing one failure creates others.”
Why you should care about evals now
Three agent dynamics reveal why teams need evals today.
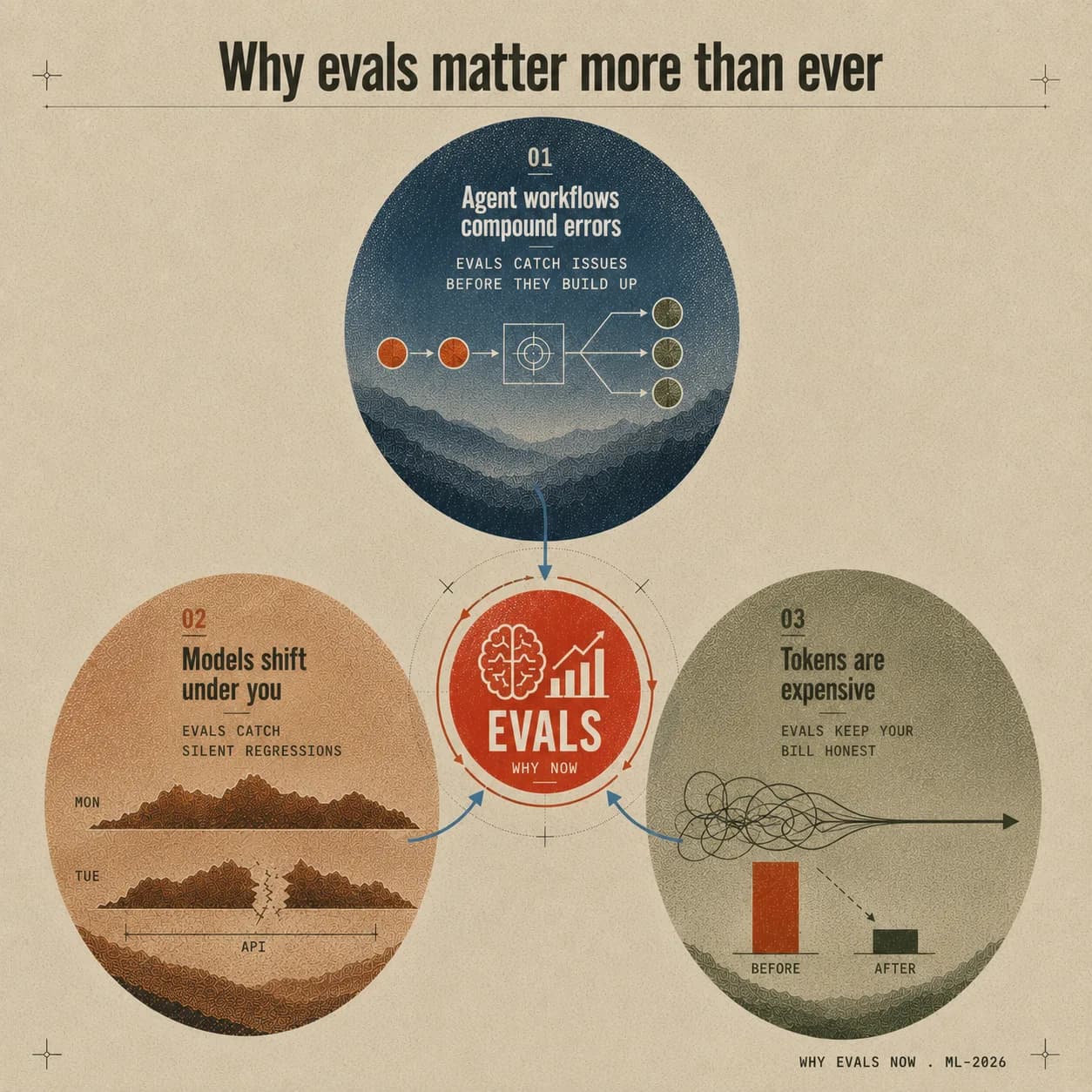
1. Agent workflows compound errors. Telemetry catches them.
People are building agent workflows now, not single chats. Modern harnesses chain agents and tools across many steps, and errors compound as they go. A wrong call at step two corrupts everything after it.
An eval harness instruments every step of that loop. Each tool call, each model response, each retry shows up as a span you can read. When a run fails, you don’t guess. You open the trace, find the step that made the wrong call, and read the reasoning that led there.
Here’s the critical difference between “the agent is flaky” and “the agent picks the wrong tool whenever the request is ambiguous at step two.” One is a shrug, the other is fixable.
2. Models shift under you. Performance varies by the day.
A provider can update a model behind the same API with no version bump, and your agent behaves differently on Tuesday than it did on Monday. New models aren’t always better on your task; they’re better on the lab’s benchmarks.
Even the labs get bitten. Anthropic’s own postmortem found a routing bug quietly degraded as much as 16 percent of Claude Sonnet 4 requests at its peak, and it ran for weeks before anyone caught it, because the evals in place didn’t measure what users were actually feeling. The drift is real enough that isclaudedumb.today now runs daily benchmarks on Claude Code.
Then there’s context poisoning, where a single bad fact enters an agent’s working state and reproduces at every step after. The Gemini 2.5 technical report documents exactly that: an agent fixating on a goal that never existed.
All of this can happen on a Tuesday, with no notice. Proactive evals catch the regression before your customers do.
3. Tokens are expensive. Evals keep the bill honest.
Analyze the full flow of an agent loop and you’ll find rampant token waste: unnecessary retries, extra tool schemas and descriptions, calls to the wrong tools entirely.
When we supported Barndoor AI, our evals found exactly this. Ask Claude to update a doc in Google Drive and it would routinely call the wrong tools, trying three or four paths before landing on the right one for a simple task. That burned thousands of tokens a run.
So we built a closed-loop system that scored the agent against common knowledge-work operations and shipped a skills pack to drive up efficiency. This was impossible without telemetry to know what the agent was doing and how to measure improvement.
Most eval libraries give you trace and span-level data on tokens, tool calls, and latency out of the box. As the industry goes from token maxxing to token stashing, that level of insight is the new table stakes.
How to get started
If you’re an AI team that hasn’t touched evals yet, don’t fret. You don’t need a platform team or a quarter of work.
- Set up telemetry and an eval harness. Easiest path is one of the leading vendors, like Arize, Braintrust, or Langfuse.
- Collect 20 to 50 real prompts from your user data and sort them into categories. For each one, decide what a good response looks like versus a bad one, and label them. Anthropic recommends drawing those first tasks straight from real production failures, where the effect sizes are largest.
- Hand the labeled examples to an LLM and use them to stand up an LLM-as-judge that grades the way you just did by hand.
- Run prompts through the system and check the judge against your own intuition. Where it disagrees with you, tune it until it tracks your judgment.
- Put the whole thing on a schedule and on triggers, every deploy and every model bump, so you catch a regression from your dashboard instead of from a customer.
Which tool
There are some great options now to quickly get started. The first three are platforms; the fourth is building your own.

In Q1, we built our own eval harness. We wired an LLM-as-judge to score Venn’s outputs for Barndoor AI and programmatically improve the skills behind them. It took MCP performance with ChatGPT to 88 percent precision on our test set, a jump of more than 20 points. That gain came straight out of the loop: the evals told us what to fix, then proved the fix worked.
The honest read is that most teams should start with a vendor. You get the tracing UI, the span data, and the scheduled-judge plumbing for free, and you spend your time on the part that’s actually yours, defining what “good” means for your agent.
Build your own when that definition is too specific for an off-the-shelf judge, or when you want the loop wired directly into how you ship.
Where this goes
Over the next six months, expect the return of the eval to be more spectacular than a Death Star explosion. Every team building a meaningful agent workflow will log its traces and evaluate performance, or it’ll fly blind.
As the data piles up, the data analysts and scientists will turn their eye to eval datasets. Pulling the full picture of product health, from model performance up to your real product KPIs, will mean working closely with data teams.
The teams who combine those datasets (evals, product metrics) into one clear view and then act accordingly will be the ones who build a real moat around their AI products.
It’s never been a more exciting time to be building evals, analytics, and AI products.
KEEP READING